Delivering agile, tech-enabled real-world evidence, market access, and HEOR solutions that leverage stakeholder insights, data-agnostic expertise, and a revolutionary engagement model to better optimize insights and evidence.

115
innovative companies supported by our work
1,000
scientific publications by current team members
3,500
experts in our stakeholder engagement network
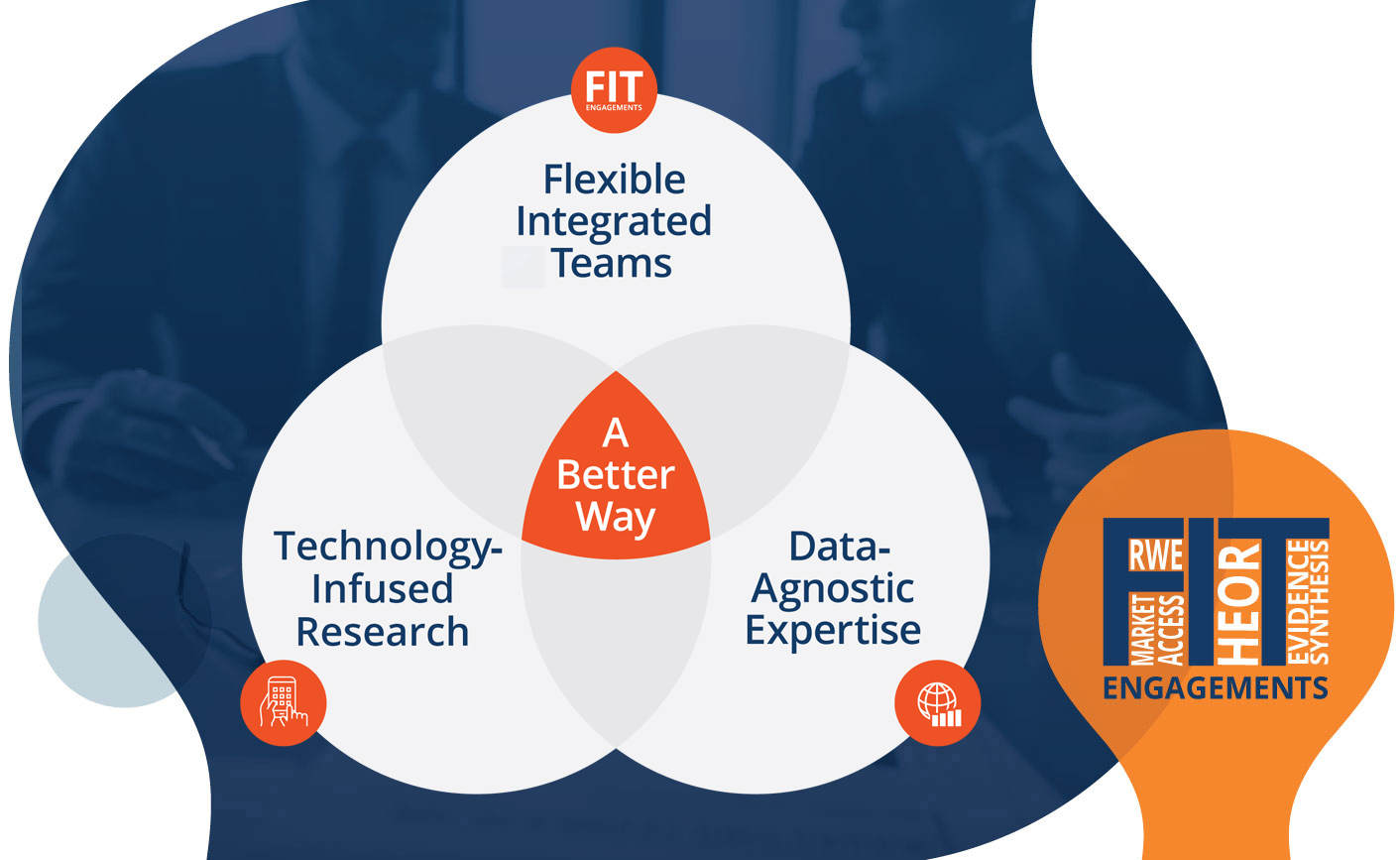
Experience the power of an integrated approach to evidence-based research
Our vision is to revolutionize healthcare research and accelerate patient access to optimal care. By taking an integrated approach that leverages fit-for-purpose data, accelerated stakeholder insights, and flexible engagements, we offer the life sciences a better way to secure efficient, impactful evidence solutions.
FIT engagement
model
Our Flexible Integrated Team (FIT) model represents a paradigm shift in how companies engage with research partners: providing expert multidisciplinary teams that adapt to your evolving research needs without the need for contractual adjustment.
Evidence-based solutions
With deep expertise in real-world evidence, HEOR, pricing, market access, literature synthesis, and scientific communications, we deliver in-depth strategic advice and impactful evidence solutions at all stages of the product lifecycle.
Where technology meets expertise
We are revolutionizing insight generation through the development of fit-for-purpose technology platforms that, supported by our expert teams, provide clients with impactful insights at an accelerated rate.
Flexible Integrated Teams (FIT)
Our team becomes your team
Take advantage of our optional FIT engagement model to secure dedicated, cross-functional teams that integrate seamlessly within your own to fill experience gaps or supplement existing resources, and which evolve over time to match your changing needs without the costly delays involved in adjusting a statement of work.
A trusted extension of your organization, our team becomes your team.
Data Agnostic RWE
Asking the right questions and accessing all relevant evidence sources
From early development to commercialization, you need the best advice and optimal data sources to support your evidence needs. Our strategic, data-agnostic approach to real-world evidence leverages global datasets and expertise without limits.
Rapid stakeholder insights
Technology-infused research
Trust the voice of the stakeholder to test your evidence strategy and optimize market access
- Leverage our agile, tech-enabled RPR platform to develop robust market access strategies and fit-for-purpose evidence-generation plans.
- Secure critical payer, KOL, patient advocacy group, and policy maker insights across the product lifecycle.
- Engage with a global network of 3,500+ vetted stakeholders across 65+ countries to test your market access and evidence strategies as they evolve.

Join our mailing list
Sign up to receive our latest thought leadership content and event invitations
1000+ scientific publications
generated by our experts
Our team members have co-authored publications across a range of therapeutic areas, data sources, indications, and methods. A selection can be seen below or view more on our online publications list.
| Title | GR Author(s) | Year | Therapeutic Area | Data Source | Journal/Conference | Full Citation & Links |
|---|---|---|---|---|---|---|
| Real-world characteristics of patients with wild-type transthyretin amyloid cardiomyopathy: an analysis of electronic healthcare records in the United States. | Crowley A, Benjumea D | 2023 | Cardiology | Optum EHR | American Journal of Cardiovascular Drugs | View |
| Benzodiazepine usage, healthcare resource utilization, and costs among older adults treated with common insomnia medications: a retrospective cohort study. | Amari DT | 2023 | Neurology | Marketscan Commercial and Medicare Supplemental | Clinicoeconomics and outcomes research | View |
| Treatment patterns and survival of patients with locoregional recurrence in early-stage NSCLC: a literature review of real-world evidence. | Brown AE | 2022 | Oncology | n/a | Medical Oncology | View |
| Assessment of the relevance and credibility of indirect treatment comparisons to help inform health technology assessment and reimbursement decision-making: results of a 5-country payer survey. | Katsoulis I, Graham A | 2023 | General Medicine | RPR Survey | ISPOR Europe | View |
| Paradigm Shift or Incremental Change? Real-World Evidence for Health Technology Assessment in Oncology. | Ignjatovic T | 2023 | Oncology | RPR Survey | ISPOR Europe | View |
Clients include
Genesis Research Hub
Headquarters:
HOBOKEN
111 River Street, Suite 1120
Hoboken, New Jersey 07030, US